graphic-前向渲染管线浅析
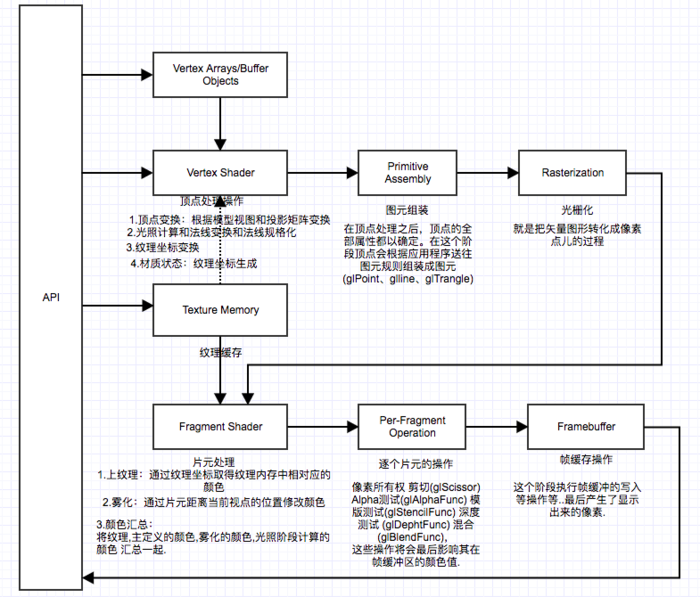
Opengl es 2.0实现了可编程的图形管线,比起1.x的固定管线要复杂和灵活很多,由两部分规范组成:Opengl es 2.0API规范和Opengl es着色语言规范。下图是Opengl es 2.0渲染管线,阴影部分是opengl es 2.0的可编程阶段。
前篇
- 渲染流水线 (不错) - https://zhuanlan.zhihu.com/p/26077873
- GPU流水线顺序和细节 - https://zhuanlan.zhihu.com/p/58845437
- 渲染管线浅析 - http://www.jianshu.com/p/d4064c237870
- Unity Shader-渲染队列,ZTest,ZWrite,Early-Z - https://blog.csdn.net/puppet_master/article/details/53900568
- Cg Programming in Unity
- 《Real-time rendering》
- 《Unity Shader 入门精要》
渲染管线 ,也称渲染流水线,是显示芯片内部处理图形信号相互独立的并行处理单元。渲染管线就是要把一系列的顶点数据,纹理等信息,最终转换成一张人眼可以看到的图像。这个过程由CPU和GPU共同完成。
渲染管线流程图(Rendering Pipeline)
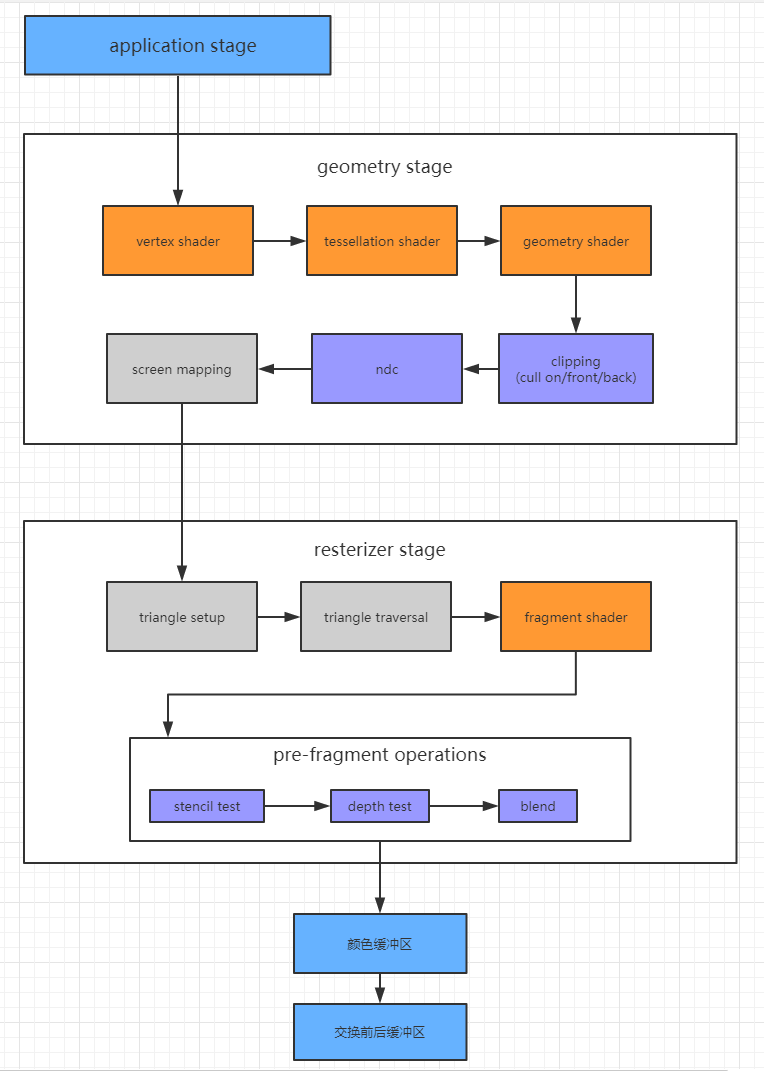
三大阶段:
Application Stage : 应用阶段,最主要的就是把我们准备好的场景数据,输出渲染需要的几何信息,即渲染图元(rendering primitives)。
Geometry Stage :几何阶段,用于处理所有和我们要绘制的几何相关的事情。
Rasterizer Stage:光栅化阶段,利用几何阶段传过来的数据产生像素,并渲染出最终的图像。
各个阶段详解
颜色表示了不同阶段的可配置性和可编程性。
- 白色:表示该阶段是由GPU固定实现,开发者没有任何控制权。
- 灰色:表示该阶段可以配置但是不可以编程。
- 橙色:实线表示可用shader编程实线,虚线表示该shader是可选的。
下面再具体多说几点:
1. Vertex Shader
对顶点数据编程的一段程序。主要工作是:坐标变换和逐顶点光照,并且为后续阶段输出所需的数据。
顶点着色器对顶点实现了一种通用的可编程方法。
顶点着色器的输入数据由下面组成:
Attributes:使用顶点数组封装每个顶点的数据,一般用于每个顶点都各不相同的变量,如顶点位置、颜色等。
Uniforms:顶点着色器使用的常量数据,不能被着色器修改,一般用于对同一组顶点组成的单个3D物体中所有顶点都相同的变量,如当前光源的位置。
Samplers:这个是可选的,一种特殊的uniforms,表示顶点着色器使用的纹理。
顶点着色器的输出数据是varying变量,在图元光栅化阶段,这些varying值为每个生成的片元进行计算,并将结果作为片元着色器的输入数据。从分配给每个顶点的原始varying值来为每个片元生成一个varying值的机制叫做插值。
2. Tessellation Shader
细分着色器, sm4.6 以后才能使用.
低模通过 置换贴图 增加曲面, 表现出高模效果
相比较 法线贴图 , 置换贴图 是真实改变顶点的位置, 会有遮挡, 而 法线贴图 只是在改变 片段 光照的视觉效果, 并不会修改模型的顶点位置.
3. Geometry Shader
几何着色器, sm4.6 以后才能使用
可以指定 n 个三角形的 顶点操作, 可以做的效果 如 破碎, mesh的每个三角随机飞离
4. Clipping
减少GPU处理数据量,把看不见的面剔除 (Cull back) 。不处理那些不在摄像机视野范围内的顶点数据, 从而可以减少 fragment shader 的计算量
这个阶段也叫 Primitive Assembly ( 图元组装 ).
图元是一个能用opengl es绘图命令绘制的几何体,绘图命令指定了一组顶点属性,描述了图元的几何形状和图元类型。顶点着色器使用这些顶点属性计算顶点的位置、颜色以及纹理坐标,这样才能传到片元着色器。在图元装配阶段,这些着色器处理过的顶点被组装到一个个独立的几何图元中,例如三角形、线、点精灵。对于每个图元,必须确定它是否位于视椎体内(3维空间显示在屏幕上的可见区域),如果图元部分在视椎体中,需要进行裁剪,如果图元全部在视椎体外,则直接丢弃图元。裁剪之后,顶点位置转换成了屏幕坐标。背面剔除操作也会执行,它根据图元是正面还是背面,如果是背面则丢弃该图元。经过裁剪和背面剔除操作后,就进入渲染流水线的下一个阶段:光栅化。
5. Screen Mapping - NDC
屏幕映射,把每个图元的x和y坐标转换到 Screen Coordinates 下。 (上面的图画错了)
可见的顶点都变为标准化设备坐标(Normalized Device Coordinate, NDC)。也就是说,每个顶点的x,y,z坐标都应该在-1.0到1.0之间,超出这个坐标范围的顶点都将不可见。我们通常会自己设定一个坐标的范围,之后再在顶点着色器中将这些坐标转换为标准化设备坐标。然后将这些标准化设备坐标传入光栅器(Rasterizer),再将他们转换为屏幕上的二维坐标或像素。
参考总结: unity-shader相关.md 中的 标准化设备坐标 ( NDC ).
6. Triangele Setup
计算一个三角形网格表示数据的过程。
7. Triangle Traversal
这里主要的工作就是找到哪些像素被三角形网格覆盖,如果覆盖了,将会得到一个片元(fragment)。
8. Fragment Shader
对像素数据编程的一段程序。这里会产生一些列数据信息,用来描述一个三角网格是怎样覆盖每个像素的。
它对光栅化阶段产生的每个片元进行操作,需要的输入数据如下:
Varying variables:顶点着色器输出的varying变量经过光栅化插值计算后产生的作用于每个片元的值。
Uniforms:片元着色器使用的常量数据
Samplers:一种特殊的uniforms,表示片元着色器使用的纹理。
Shader program:片元着色器的源码或可执行文件,描述了将对片元执行的操作。
片元着色器也可以丢弃片元或者为片元生成一个颜色值,保存到内置变量gl_FragColor。光栅化阶段产生的颜色、深度、模板和屏幕坐标(Xw, Yw)成为流水线中pre-fragment阶段
9. Per-Fragment Operations
逐个片元操作阶段. 这里主要是淘汰一些不合格的片元以及如何合并问题。这里涉及了很多测试工作,如:模板测试(Stencil Test),深度测试(Depth Test)。而如果一个片元成功通过所有测试,就需要把这个片元的颜色值和已经存储在颜色缓冲区中的颜色进行合并,最终输出我们看到的图像。依次进行
stencil test
模板测试, 指定模板 掩码值, 并指定一系列条件 (是否保留, 替换 掩码值等). 与 模板缓冲区 对应像素点的 掩码值 进行比较.
depth test
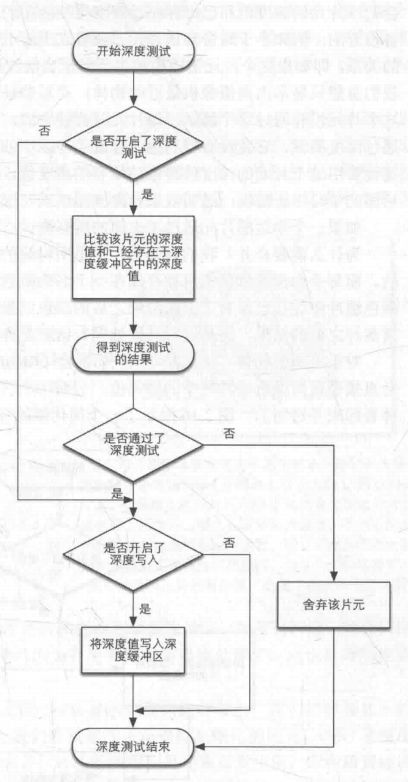
深度测试. 指定深度比较的方式 并且 指定是否写入深度. 如果符合条件有写入深度的话, 会更新 深度缓冲区 对应像素点的 深度值.
深度测试现在的 gpu 可以根据配置指定是否要提前, 参考: 深度测试提前:Early-Z技术
blend
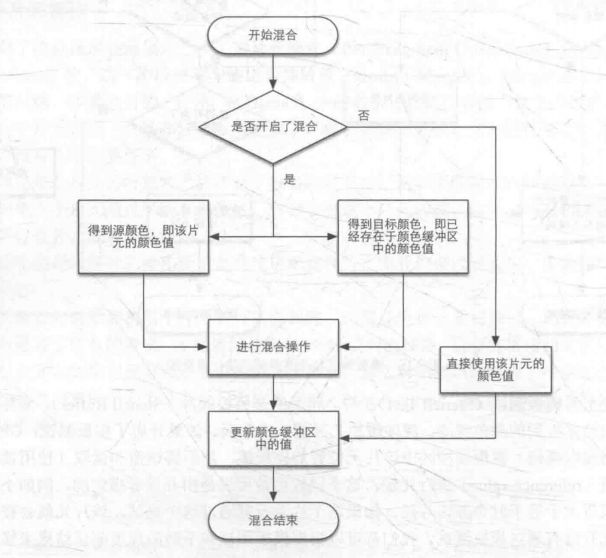
颜色混合. 使用 当前像素点与 颜色缓冲区对应的像素点进行颜色混合, 混合方式可以自定义.
深度测试提前:Early-Z技术
现代的大多数 GPU为了提高性能,会尽量将测试提前到片元着色器之前进行。
这是可以理解的:想象一下,当GPU在经过片元着色器进行大量的计算终于得到片元的颜色了,在进行可见性检测的时候却发现这些片元根本无效,此时才把他们舍弃掉,那么之前的计算都白费了。
这种将深度测试提前的技术叫做Early-Z技术。如 Unity 给出的渲染流水线中深度测试就在片元着色器之前:

如果我们先绘制后面的物体,再绘制前面的物体,就会造成over draw;而通过Early-Z技术,我们就可以先绘制较近的物体,再绘制较远的物体(仅限不透明物体),这样,通过先渲染前面的物体,让前面的物体先占坑,就可以让后面的物体深度测试失败,进而减少重复的fragment计算,达到优化的目的。Unity中默认应该就是按照最近距离的面进行绘制的
从文档给出的流程来看,这个Depth-Test发生在Vertex阶段和Fragment阶段之间,也就是上面所说的Early-Z优化。
简单总结一下Unity中的渲染顺序:
先渲染不透明物体,顺序是从前到后;
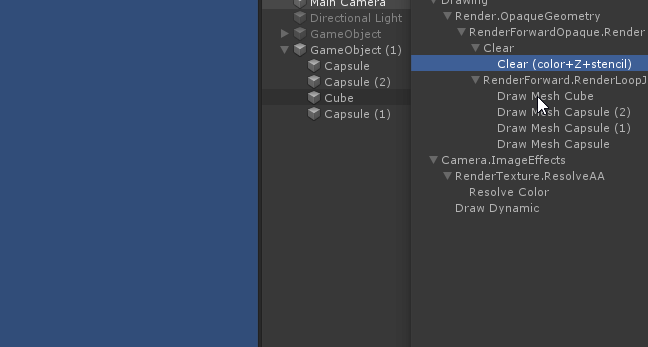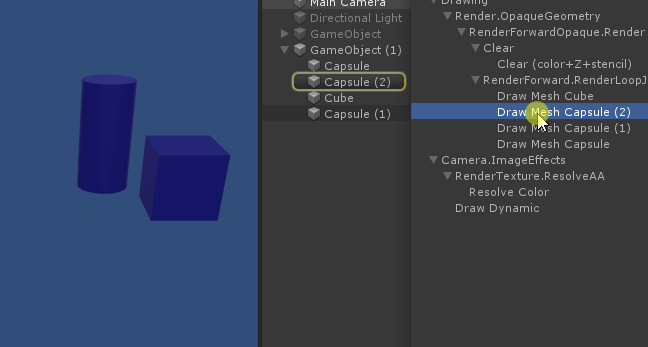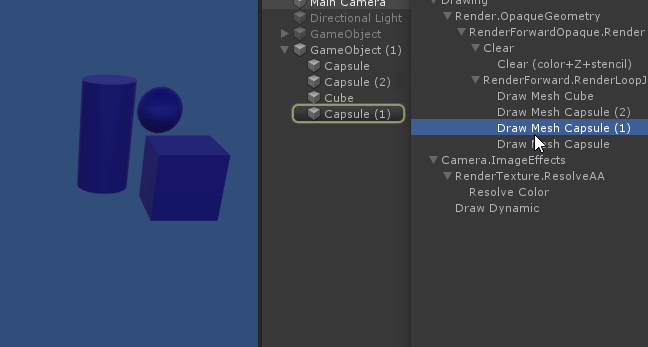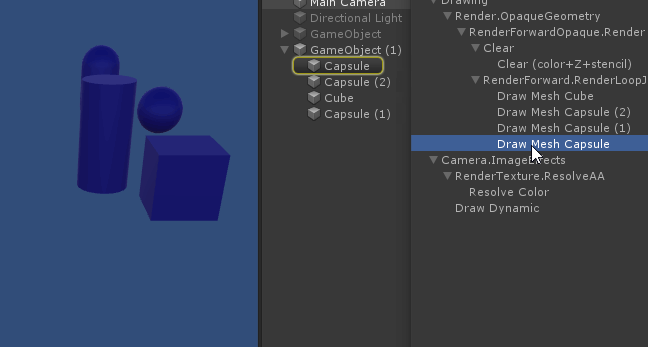
再渲染透明物体,顺序是从后到前
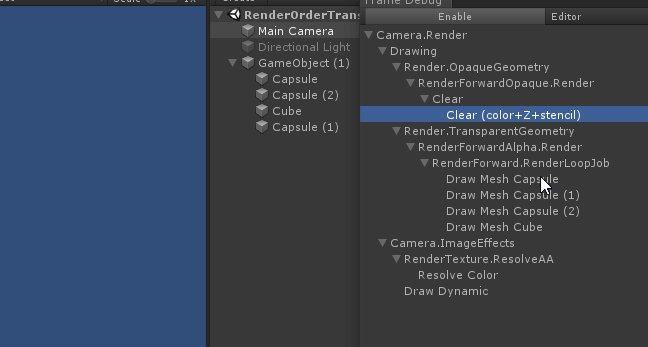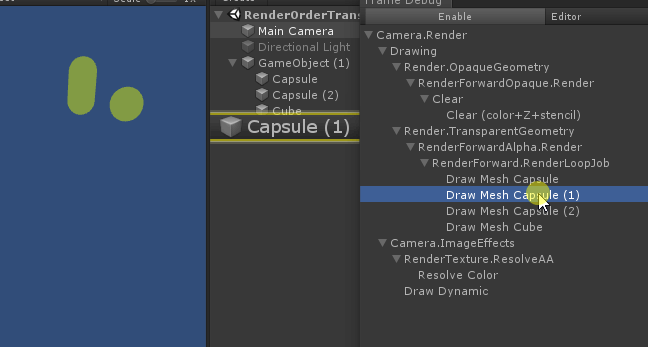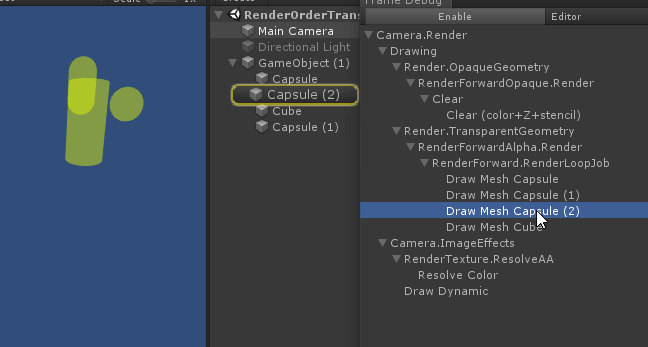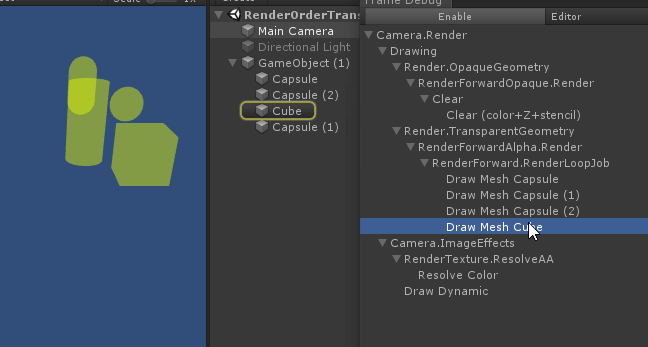
但是 深度测试提前 可能会与片元着色器中的一些操作冲突:比如在开启了 透明测试 情况下,已经通过了深度测试,但片元进行透明测试时失败,我们会手动使用clip函数将片元舍弃掉。这样就导致GPU无法使用 深度测试提前 了。
现代GPU会判断片元着色器中是否有与 深度测试提前 相冲突的操作,如果有就会禁用 深度测试提前,但是这样就会造成性能的下降,因为要经过片元着色器进行处理的片元更多了,这也是透明测试造成性能下降的原因。参考: [Alpha Test(Discard)在移动平台消耗较大的原因](#Alpha Test(Discard)在移动平台消耗较大的原因)
其他文章: 深入剖析GPU Early Z优化 - https://zhuanlan.zhihu.com/p/53092784
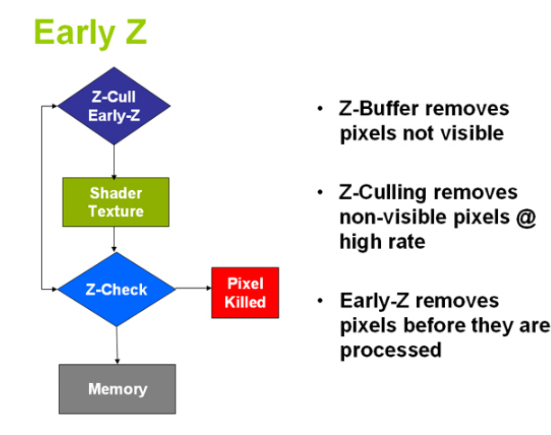
Early-Z技术
传统的渲染管线中,ZTest其实是在Blending阶段,这时候进行深度测试,所有对象的像素着色器都会计算一遍,没有什么性能提升,仅仅是为了得出正确的遮挡结果,会造成大量的无用计算,因为每个像素点上肯定重叠了很多计算。因此现代GPU中运用了Early-Z的技术,在Vertex阶段和Fragment阶段之间(光栅化之后,fragment之前)进行一次深度测试,如果深度测试失败,就不必进行fragment阶段的计算了,因此在性能上会有很大的提升。但是最终的ZTest仍然需要进行,以保证最终的遮挡关系结果正确。前面的一次主要是Z-Cull为了裁剪以达到优化的目的,后一次主要是Z-Check,为了检查,如下图:
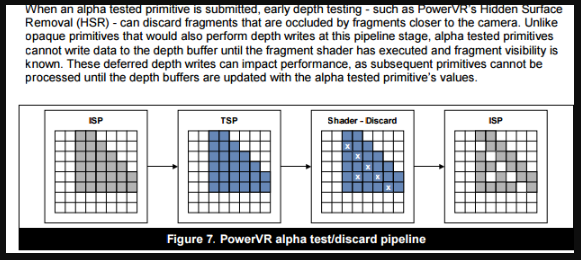
Alpha Test(Discard)在移动平台消耗较大的原因
正常情况下,比如我们渲染一个面片,不管是否是开启深度写入或者深度测试,这个面片的光栅化之后对应的像素的深度值都可以在Early-Z(Z-Cull)的阶段判断出来了;而如果开启了Alpha Test(Discard)的时候,discard这个操作是在fragment阶段进行的,也就是说这个面片光栅化之后对应的像素是否可见,是在fragment阶段之后才知道的,最终需要靠Z-Check进行判断这个像素点最终的颜色。其实想象一下也能够知道,如果我们开了Alpha Test并且还用Early-Z的话,一块本来应该被剃掉的地方,就仍然写进了深度缓存,这样就会造成其他部分被一个完全没东西的地方遮挡,最终的渲染效果肯定就不对了。所以,如果我们开启了Alpha Test,就不会进行Early-Z,Z Test推迟到fragment之后进行,那么这个物体对应的shader就会完全执行vertex shader和fragment shader,造成over draw。有一种方式是使用Alpha Blend代替Alpha Test,虽然也很费,但是至少Alpha Blend虽然不写深度,但是深度测试是可以提前进行的,因为不会在fragment阶段再决定是否可见,因为都是可见的,只是透明度比较低罢了。不过这样只是权宜之计,Alpha Blend并不能完全代替Alpha Test。
关于Alpha Test对于Power VR架构的GPU性能的影响,简单引用一下官方的链接以及一篇讨论帖:
最后再附上两篇参考文章
不同几种剔除(Culling)在渲染流程中的使用总结
原文链接: https://blog.csdn.net/game_fengxiaorui/article/details/79958722
涉及到的剔除方法包括:
- 视椎体剔除
- 遮挡剔除
- 视口剔除
- 背面剔除
- 深度剔除
模板测试 流程
深度测试 流程
混合 流程
附: OpenGL_ES_2.0渲染管线流程图