media-有声小说工作流详解
media-有声小说工作流详解
前篇
之前玩了一星期的头条有声动漫小说, 用了两个小号去玩了下有声小说内容, 这里就详细说一下这个工作流.
有声动漫小说 这个内容起号还是挺好的, 而且内容有粘性, 播放量也不错. 找下时下比较流行的动漫小说, 然后就可以用这个工作流制作头条内容让后上传, 熟悉流程后基本一天花不到一个小时的时间就可以完成 60 个视频的制作 (不包含视频渲染时间, 每个视频 3 分钟左右)
然鹅….开始劝退
虽然这样的制作是可以完美过审, 躲过头条的审核机制, 但是毕竟小说内容也是有版权的, 还是有点风险的, 可能会一朝回到解放前………
我的两个小号已清空放弃, 哈哈哈, 还是建议原创.
流程
1. 获取小说内容
用 Python 写个爬虫爬取小说内容, 可以去 https://www.51shucheng.net/ 爬取, 这个网站的内容没有用 异步加载, 直接 http get 一下就可以获取到全部小说内容, 中间也不会掺杂一些广告之类的无用内容, 爬取到的内容可以直接拿去文本转语音
python 使用 lxml 库去解析 html 内容, 示例代码
```python
import unittest
from lxml import etreePython解析库lxml与xpath用法总结 - https://www.cnblogs.com/dcpeng/p/14528019.html
class Test_Lxml(unittest.TestCase):
def setUp(self): print("\n\n------------------ test result ------------------") def test_xpath(self): # 作为示例的 html文本 htmlTxt = '''<div class="container"> <div class="row"> <div class="col"> <div class="card"> <div class="card-content"> <a href="#111" class="box111"> 点击我 111 </a> <a href="#222" class="box222"> 点击我 222 </a> <a href="#333" class="box333"> 点击我 333 </a> </div> </div> </div> </div> </div>''' # 对 html文本进行处理 获得一个_Element对象 html = etree.HTML(htmlTxt) # xpath 规则和 selenium 差不多 # 获取 a标签下的文本 aTextArr = html.xpath('//div/div/div/div/div/a/text()') # xpath 获取到的都是数组 print("--- aTextArr:", aTextArr) aHrefArr = html.xpath('//div/div/div/div/div/a/@href') print("--- aHrefArr:", aHrefArr) aEleArr = html.xpath('//div/div/div/div/div/a') print("--- aEleArr:", aEleArr) print("--- aEleArr 111:", aEleArr) aEle = aEleArr[0] print("--- txt 111: {}, href: {}, class: {}".format(aEle.text, aEle.attrib.get('href'), aEle.attrib.get('class'))) aEleArr = html.xpath('//div/div/div/div/div/a[2]') # 数组下标从 1 开始, 返回同样是个数组 print("--- aEleArr 222:", aEleArr) aEle = aEleArr[0] print("--- txt 222: {}, href: {}, class: {}".format(aEle.text, aEle.attrib.get('href'), aEle.attrib.get('class')))
2. 生成 语音文件
使用 微软 文字语音, 生成 音频 文件, 详细可以参考之前写的 media-微软Azure文字转语音
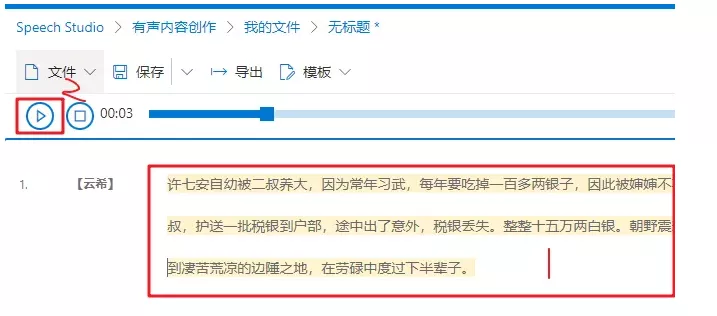
3. 生成 字幕
使用 剪映 的 文稿匹配 音频 和 小说内容, 就可以生成字幕文件
这个字幕不用导出, 它会缓存到用户目录下某个文件夹, 下一步 pr 的插件可以抓取并导入这个字幕文件
这个动图里面是错的(懒得录制了), 要选择 文稿匹配, 输入文稿, 就可以和语音内容的匹配上
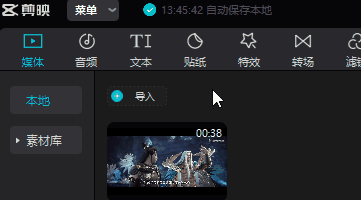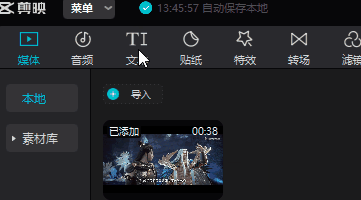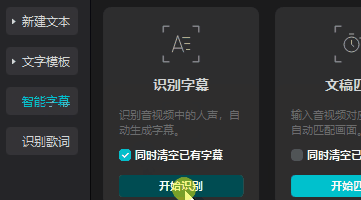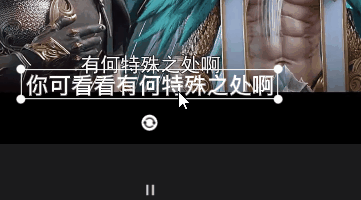
(ps: 如果内容分成几段匹配时, 要先 隐藏 or 删除 之前的 音频 和 字幕, 不然第二段匹配会出现问题)
4. 剪辑
剪映字幕插件
安装 pr 插件 Q_Chameleon. (下载地址: ZXP安装程序-AE Pr 插件管理神器)
(ps: 貌似要 pr 2020+ 才能使用)

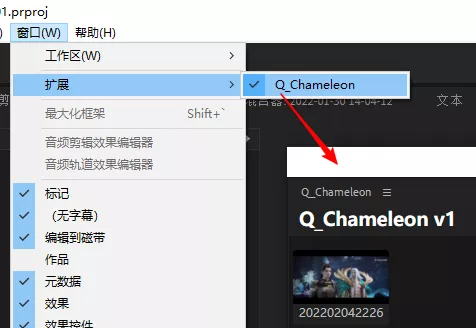
pr 中打开 Q_Chameleon 插件
窗口 -> 扩展 -> Q_Chameleon, 就可以看到刚才剪映生成字幕的素材.
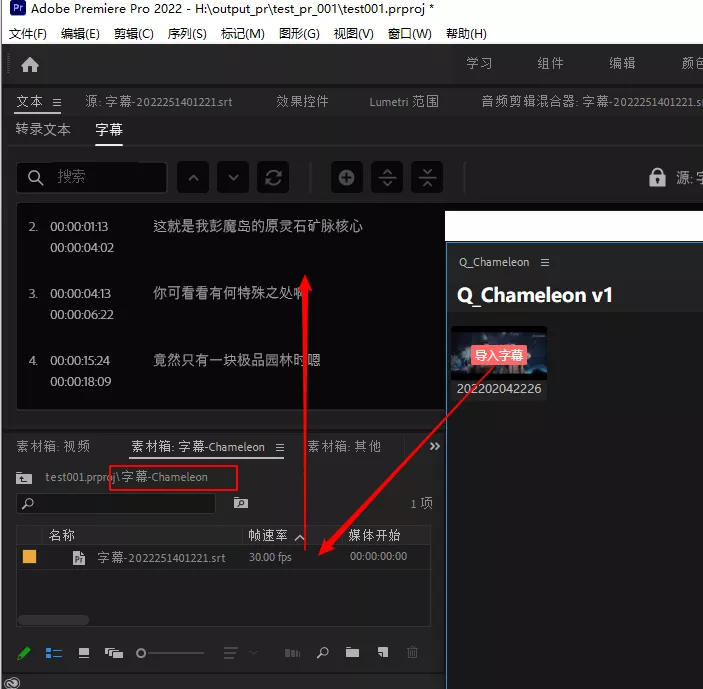
点击 导入字幕 会将字幕导入到 素材窗口 根目录下, 自动生成的 字幕-Q_Chameleon 目录里面.
步骤
加入 使用 生成的语音文件, 字幕文件
加入 视频素材, 随机切片, 随机调换顺序, 全部加入转场过渡
视频素材最好不要时下流行的动漫, 最好找一些乱七八糟的动漫素材, 如油管里有个 EDM For You 就很多素材可以用, 传送门: https://www.youtube.com/c/EDMForYouMusic

剪辑后的效果如下:
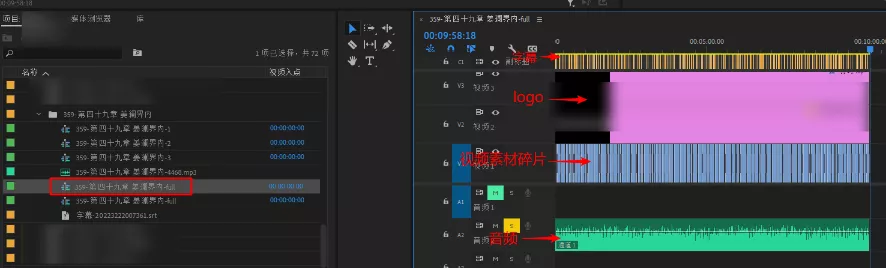
将这个序列 右键 -> 从剪辑新建序列 生成一个新序列, 用来分割成 3 段, 右键 -> 嵌套 生成 3 个序列, 每段大概就 3 分钟左右
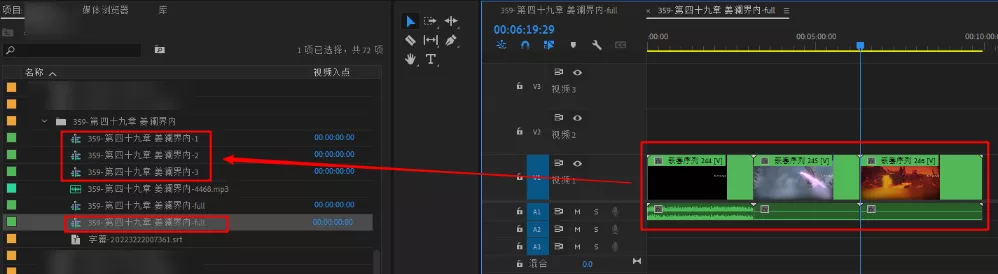
将分割后的 3 个序列导出到 Encoder 队列中
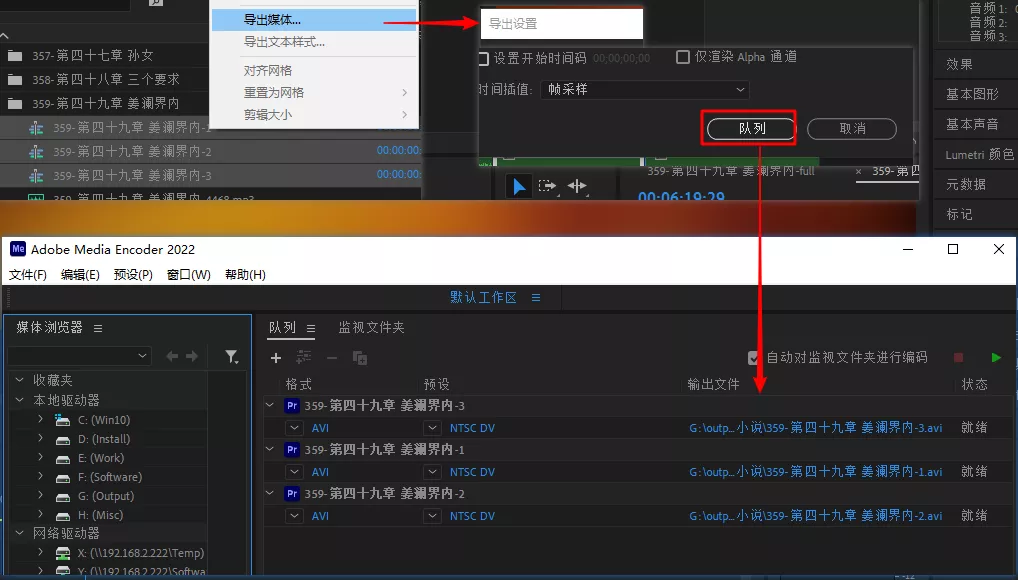
多制作一些导入到 encoder 中, 在电脑空闲时间就可以开始渲染出视频
5. 上传平台
- 上传到头条里面, 过审后在加入合集里, 因为在合集里面, 用户才可以连续播放里面的内容, 可以提高播放量
- 每个号每天上传的限制应该是 30 个, 可以将不同小说分成不同的号去弄.
- 至此, 结束.