go-游戏服务器
go-游戏服务器
前篇
- Golang 游戏架构简介 - https://www.jianshu.com/p/546773568592
- 游戏服务器架构通识 - https://zhuanlan.zhihu.com/p/28447002
- 游戏服务器框架 - https://zhuanlan.zhihu.com/p/35014832
- 游戏服务器架构的演进简史 - https://www.infoq.cn/article/a-brief-history-of-the-game-server-architecture
- 经典游戏服务器端架构概述 - https://cloud.tencent.com/developer/article/1164964
- 游戏服务器架构概要 - https://gameinstitute.qq.com/course/detail/10090
- Go 在马蜂窝即时通讯服务建设中的实践 - https://www.toutiao.com/a6776111164251177486/
- 入 Go 必读:大型Go工程的项目结构及实战思考 - https://www.toutiao.com/i6856899918293336588/
- 如何保证APP与API通信安全,TOKEN冒用带来的风险很大? - https://www.wukong.com/answer/6810240995020521735/
视频教程
视频教程, 分析数据库等底层源码实现, 非常好 - https://www.ixigua.com/home/95168201176/video/
- mysql
- 1天掌握MYSQL数据库,这应该是B站最详细的Mysql底层源码解析了 - https://www.ixigua.com/i6762489842027725325
- 超级详细的Mysql数据库面试知识点总结(进阶篇) - https://www.ixigua.com/i6772130552771248644
- 深入理解MySQL,简历上再说熟悉数据库 - https://www.ixigua.com/i6768033887646908940
- MySQL大型分布式集群Mycat分库分表实战 - https://www.ixigua.com/i6759127813309104654
- 大厂在用的数据库Mycat分库分表方案,都在这了! - https://www.ixigua.com/i6774716275655442947
- Java分布式架构之最详细的Mycat分库分表入门到精通 - https://www.ixigua.com/i6751704362382262788
- 2019最新Mysql数据库面试必问视频教程 - https://www.ixigua.com/i6751333359642739214
- 【JAVA高质量】MYSQL8降序索引从入门到精通视频教程 - https://www.ixigua.com/i6719415617167819278
- 【Mysql】数据库Mysql从入门到精通视频教程 - https://www.ixigua.com/i6705984812718490120
- Redis
- 12月最新深入讲解redis数据结构扩展,搞明白了你就是Redis高手! - https://www.ixigua.com/i6766576665632965123
- 【Redis高级面试课】看完以后面试再也不怕问Redis了! - https://www.ixigua.com/i6760254700844483084
- 【Redis面试总结】深入Redis,详解Redis持久化机制的原理! (和下面的差不多) - https://www.ixigua.com/i6773242122746200579
- 【Java面试必看】全网最牛逼的Redis持久化机制讲解视频教程 - https://www.ixigua.com/i6724228988606087687
- 这些Redis的面试题80%的程序员面试者都不知道! - https://www.ixigua.com/i6764702037427880451
- 10月最新的Redis入门到进阶教程,程序员值得一看! - https://www.ixigua.com/i6747642797131563528
- 2019最详细的Redis集群架构视频教程 - https://www.ixigua.com/i6740199900648047111
- 【Java程序员面试必备】大牛带你深入缓存穿透-缓存击穿解决方案 - https://www.ixigua.com/i6720518099243647495
- 数据库常见面试题全套视频教程,Java开发者必备必看(Redis+Mysql+分库分表)- 连接
- 分布式
- 阿里面试中分布式事务解决方案的回答方法 - https://www.ixigua.com/i6761747734748725774
- 大厂面试必知必会:常用的分布式事务解决方案介绍有多少种? - https://www.ixigua.com/i6775825798373835276
- 再有人问你分布式事务,把这视频扔给他!! - https://www.ixigua.com/i6741330969011159560
- 再有人问你分布式事务,把这视频扔给他!!(补发上一期)https://www.ixigua.com/i6742077753610207758
- 【Java微服务架构】程序员必备的分布式事务框架详解 - https://www.ixigua.com/i6719779283486638599
- 2019最详细的一线互联网大厂Java分布式ID生成器解决方案 - https://www.ixigua.com/i6735790612198457864
- 【Java分布式系列】编程必备Java面试技巧-千万海量数据缓存架构 - https://www.ixigua.com/i6723118997706899975
- docker
- 2019最详细的Docker实战部署项目视频教程 - https://www.ixigua.com/i6707941438857937416
- 【Docker】2020最新docker构建微服务框架,容器化技术全解 - https://www.ixigua.com/i6778797649999954440
- 【JAVA微服务】Docker实战从入门到精通视频教程 - https://www.ixigua.com/i6714997884829303303
- 什么是负载均衡原理?Java分布式负载均衡算法介绍 - https://www.ixigua.com/i6732811450642858510
- 2019最新的大数据从入门到精通的视频教程 - https://www.ixigua.com/i6728316599129883144
常见架构
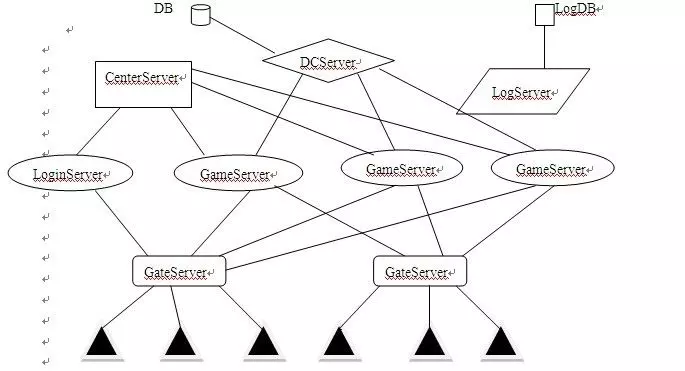
以上是比较常见的结构,客户端登录的时候,连接GateServer,然后由GateServer去连接LoginServer进行登录。登录后通过CenterServer转发到GameServer(GameServer即是服务器大区)。而其中的DCServer,主要的功能是缓存玩家角色数据,保证角色数据能快速的读取和保存。LogServer便是保存日志的了。
优秀开源库
有个不错的汇总仓库 - https://github.com/yinggaozhen/awesome-go-cn
- json
- 高性能,100% 兼容的“encoding/json” 替代品 - https://github.com/json-iterator/go
开发环境
docker
统一环境, 方便部署迁移.
定时器
定时 检测心跳, 推送 等
GM
gm 服务器, 用于控制台输入指令, 连接上各个服务器, 对输入指令做响应的业务处理.
比如:
- 连上 game 服务器, 执行 关服 指令, 关掉 中心服 Agent 与 在线人数推送, 让 负载服务器 (可以是 login 服务器) 去掉这个 game 服务器的 addr.
- 连上 目标服务器 重新 load 配置表, 剔除某些玩家 等等.
事件系统
解耦模块间的关联
数据库
可以直接购买 阿里云 的 云数据库, 不需要自己 租服务器后再搭建 数据库服务
- 游戏服务器使用MongoDB作为数据库,还有必要使用Redis缓存吗? - https://www.zhihu.com/question/29775064
- 网络游戏服务器与数据库的关系? - https://www.zhihu.com/question/21112656
- 记录一次MySQL两千万数据的大表优化解决过程,提供三种解决方案 - https://database.51cto.com/art/201902/592522.htm
数据库层 需要与 业务层 隔离, 提供对外接口, 业务层不需要关心使用什么数据库, 只管接口调用.
选型
- 谈谈mongodb,mysql的区别和具体应用场景 - https://blog.csdn.net/shark1621/article/details/81097472
- mongodb与mysql区别(超详细) - https://blog.csdn.net/Gjc_csdn/article/details/80419997
Mysql和Mongodb主要应用场景
如果需要将mongodb作为后端db来代替mysql使用,即这里mysql与mongodb 属于平行级别,那么,这样的使用可能有以下几种情况的考量: (1)mongodb所负责部分以文档形式存储,能够有较好的代码亲和性,json格式的直接写入方便。(如日志之类) (2)从datamodels设计阶段就将原子性考虑于其中,无需事务之类的辅助。开发用如nodejs之类的语言来进行开发,对开发比较方便。 (3)mongodb本身的failover机制,无需使用如MHA之类的方式实现。
将mongodb作为类似redis ,memcache来做缓存db,为mysql提供服务,或是后端日志收集分析。 考虑到mongodb属于nosql型数据库,sql语句与数据结构不如mysql那么亲和 ,也会有很多时候将mongodb做为辅助mysql而使用的类redis memcache 之类的缓存db来使用。 亦或是仅作日志收集分析。
读写分离
分摊压力, 做好主从同步, 一主库 只写, 多从库 只读, 连接池 连到不同的从库, 也可以通过 hash 取模 获取到连接池中 目标数据库
MySQL
- MySQL言操作mysql数据库 - https://studygolang.com/articles/3022
- golang操作mysql使用总结 - https://studygolang.com/articles/12509
使用时要引入两个库, 不然会报错
1 | import ( |
防注入
- Golang MySQL 驱动中的 Prepare 语句(防 SQL 注入) - https://learnku.com/go/t/49692
- 避免 SQL 注入 - https://learnku.com/docs/build-web-application-with-golang/094-avoids-sql-injection/3212
- Go语言SQL注入和防注入 - https://studygolang.com/articles/26988
两种模式
Query(query string, args …interface{}) 函数根据是否存在 args 参数有两种模式.纯文本模式
如果在没有 args 的情况下调用 Query(query), 我将其称为 纯文本模式.在此模式中,驱动程序不对查询字符串进行任何操作,而是直接将其发送到 MySQL 服务器.
插值模式
如果查询字符串中有一些占位符 (例如 MySQL 中的 ?) 并传入了一些 args 进行插值,我会调用 ‘ 插值模式 ‘.在此模式中,驱动程序实际执行 3 个动作
准备一个语句.
使用给定的 args 执行准备好的语句.
关闭准备好的语句.
正如预备语句的口号: Prepare Once, Execute Many.
SQL注入判断
执行登录查询的数据库语句:
"SELECT * FROM userinfo WHERE username ='"+sename+"'AND password ='"+partname+"'"当查询到数据表中存在同时满足 username 和 password 字段时,会返回用户信息。 尝试在用户名中输入 123’ or 1=1 #, 密码同样输入 123’ or 1=1 # ,实际执行的SQL语句是
select * from users where username='123' or '1'='1' and password='123' or '1'='1则会出现一个空白页面,其实此时SQl注入已经绕过验证进入到需要身份验证的页面。
而如果执行
"SELECT * FROM userinfo WHERE username = ? AND password = ?", sename, partname再次输入123’ or 1=1 #,则会被拦截下来,显示无该用户数据。
为什么参数化查询会防止SQL注入
我们需要知道参数化查询都做了些什么事:
参数过滤
执行计划重用
它的原理是采用了预编译的方法,先将SQL语句中可被客户端控制的参数集进行编译,生成对应的临时变量集,再使用对应的设置方法,为临时变量集里面的元素进行赋值,而QueryRow()方法会对传入参数进行强制类性检查和安全检查,所以就避免了SQL注入的产生。
1
QueryRow("SELECT * FROM userinfo WHERE username = ? AND password = ?", sename, partname).Scan(&uid, &username, &password)
性能
这意味着
纯文本模式比插值模式有着更好的性能.
这是合理的,因为插值模式下的每个Query()或Exec()必须执行 3 次网络通信.结论
- 插值模式 可用于规避大多数 SQL 注入,这是非常重要的一点。因此,强烈建议使用它来规避用户输入参数中可能的 SQL 注入.
- 纯文本模式 在某种程序上具备更好的性能。但是,也有一些方法可以加快 插值模式 ,
防注入
- 严格限制 Web 应用的数据库的操作权限,给此用户提供仅仅能够满足其工作的最低权限,从而最大限度的减少注入攻击对数据库的危害。
- 检查输入的数据是否具有所期望的数据格式,严格限制变量的类型,例如使用 regexp 包进行一些匹配处理,或者使用 strconv 包对字符串转化成其他基本类型的数据进行判断。
- 对进入数据库的特殊字符(’”\ 尖括号 &*; 等)进行转义处理,或编码转换。Go 的 text/template 包里面的 HTMLEscapeString 函数可以对字符串进行转义处理。
- 所有的查询语句建议使用数据库提供的参数化查询接口,参数化的语句使用参数而不是将用户输入变量嵌入到 SQL 语句中,即不要直接拼接 SQL 语句。例如使用 database/sql 里面的查询函数 Prepare 和 Query,或者 Exec(query string, args …interface{})。
- 在应用发布之前建议使用专业的 SQL 注入检测工具进行检测,以及时修补被发现的 SQL 注入漏洞。网上有很多这方面的开源工具,例如 sqlmap、SQLninja 等。
- 避免网站打印出 SQL 错误信息,比如类型错误、字段不匹配等,把代码里的 SQL 语句暴露出来,以防止攻击者利用这些错误信息进行 SQL 注入。
MongoDB
- MongoDB 官方文档 : http://www.mongoing.com/archives/27257
- MongoDB 应用场景? - https://www.zhihu.com/question/32071167
go 中使用 MongoDB 官方库需要用到 gcc, 不然会报错: go exec: "gcc": executable file not found in %PATH%
下载 mingw64, 把 bin 目录路径丢到环境变量中即可.
如果你还在为是否应该使用 MongoDB,不如来做几个选择题来辅助决策(注:以下内容改编自 MongoDB 公司 TJ 同学的某次公开技术分享)。
应用特征Yes / No应用不需要事务及复杂 join 支持必须 Yes新应用,需求会变,数据模型无法确定,想快速迭代开发?应用需要2000-3000以上的读写QPS(更高也可以)?应用需要TB甚至 PB 级别数据存储?应用发展迅速,需要能快速水平扩展?应用要求存储的数据不丢失?应用需要99.999%高可用?应用需要大量的地理位置查询、文本查询?
如果上述有1个 Yes,可以考虑 MongoDB,2个及以上的 Yes,选择MongoDB绝不会后悔。
分页优化
不同数据库都差不多, 先利用 条件 (如: 主键) 进行偏移, 判断 > id 在 limit
orm
貌似性能比较低, 不推荐, 自己写 dao 靠谱点.
- 在Github中stars数最多的Go数据库框架集合 - https://juejin.im/entry/59b243a3f265da24754db898
- https://github.com/astaxie/beego/tree/master/orm
- https://github.com/jinzhu/gorm
- https://github.com/go-xorm/xorm
分库分表中间件
分库分表好处是分摊访问压力, 但是如果查询的时候, 如果查的不是分库的键 (uid hash 取模), 比如查 name 字段, 那么就有可能需要全部查询一遍
- Mycat
缓存
- 腾讯互娱架构师谈游戏服务器缓存系统怎么造 - https://dbaplus.cn/news-160-909-1.html
- 游戏服务器缓存redis 大致作用 - https://www.jianshu.com/p/664bcda63cc1
缓存的目的是 提高数据访问性能 和 减少集中并发访问数据库.
热点数据存在缓存中以提高访问性能, 减少 数据库 访问压力.
使用 布隆过滤器 过滤无效查询.
Redis
内存数据库
- golang-redis教程 - https://www.tizi365.com/archives/296.html
- redis数据库与go中的使用 - https://www.jianshu.com/p/3f4297b6bff9
订阅/发布
- golang中redis对redigo的发布订阅机制的使用 - https://blog.csdn.net/qq_17308321/article/details/89417493
- golang redis发布订阅 - https://www.tizi365.com/archives/306.html
热点数据 预存储
- 开服时 先将关键信息从数据 load 到缓存中, 如: 登录时玩家的 uid 为 key, val 值 map, 先存放 密码 等登录信息, 以提高登录验证性能
- 游戏过程中先从缓存取, 取不到再从数据库中取
日志
首选 zap 是 uber 开源的 Go 高性能日志库 https://github.com/uber-go/zap
- golang高性能日志库zap配置示例 - https://www.jianshu.com/p/b0de3b46e63f
切割日志
可以按 大小/时间 来切割日志.
- GitHub - https://github.com/natefinch/lumberjack
- Golang zap和lumberjack实现日志存储和自动管理 - https://blog.csdn.net/skh2015java/article/details/107234908
日志入库
专门起一个 进程监听日志文件变化, 增加的日志到达一定数量 (比如: 10条) 就把增加的日志发到 日志服/数据库
可以使用这个库: https://github.com/hpcloud/tail
切割日志
服务注册于发现
etcdv3
- golang游戏项目中使用 tls、https 与etcd v3服务通讯 - https://www.cnxct.com/use-tls-https-to-transport-with-etcd-server-in-golang-gameserver/
- etcd 的 go sdk 的使用方法 - https://www.lijiaocn.com/%E7%BC%96%E7%A8%8B/2019/06/19/etcd-go-sdk-clientv3-usage.html
分布式
唯一ID
- 分布式系统唯一ID生成方案汇总 - https://www.cnblogs.com/wyb628/p/7189772.html
- 高并发环境下系统生成全局唯一ID - https://www.jianshu.com/p/eab6eb4e6b35
MySQL 唯一 id 从某个值开始自增
insert 一条临时数据, id 为 12516075
1
2stmt, _ := dbw.Db.Prepare(`INSERT INTO user (id, name, age) VALUES (?, ?, ?)`)
ret, err := stmt.Exec(12516075, "xys", 25)此后 insert 都在这个值的基础上自增1
有 insert 正常数据进来后, 可以 delete 掉 id 为 12516075 的临时数据
分布式 锁
事务
- 常用的分布式事务解决方案 - https://juejin.im/post/5aa3c7736fb9a028bb189bca
- 再有人问你分布式事务,把这篇扔给他 - https://juejin.im/post/5b5a0bf9f265da0f6523913b
服务 注册/发现
etcdv3 是个不错的选择, 参考: go-micro服务发现etcd.md
也可以自己起个中心服务器
rpc
- 多服务间的 rpc 一般使用 protobuf 编码解码消息.
- 第一条消息 必须为 握手协议, 证明是来自自己的服务连接, 还有超时机制, 黑名单模式.
配置表 Excel
用于给策划配置游戏内一些 可变 的参数
配置文件
用于服务启动, 游戏内 固定 参数 配置
可以使用 yaml, json 等格式, 一般使用 yaml 格式, 可以添加注释, json 不能添加注释.
网络
- echo 框架
- gin - https://github.com/gin-gonic/gin
- 官网 - https://gin-gonic.com/
- star : 35k
- labstack - https://github.com/labstack/echo
- 官网 - https://echo.labstack.com/
- star : 16k
- evio - https://github.com/tidwall/evio (比标准库高性能的网络库, 包含 tcp/udp/http, http 比 fasthttp 还高性能)
但是作为 tcp 的话只能是 echo 模式, 也就是不能主动推送, 只能调用返回- star : 4k
- gin - https://github.com/gin-gonic/gin
Http
- fasthttp, 据说是目前golang性能最好的http库,相对于自带的net/http,性能说是有10倍的提升
- 仓库 - https://github.com/valyala/fasthttp
- golang使用fasthttp 发起http请求 - https://juejin.im/post/5c3dc85f51882524f2302ce6
- router 路由
- https://github.com/julienschmidt/httprouter
- 使用fasthttp搭建go的web服务器 - https://zhuanlan.zhihu.com/p/52644362
tcp
tcp协议可靠吗? 怎么知道自己发出的消息已经被是否被成功接收? - https://www.zhihu.com/question/25013499

actor 模式
每一个 actor 分配两个 goroutine (一读一写)
tcp 断包 粘包 问题
为什么会出现 断包 和 粘包?
客户端一段时间内发送包的速度太多,服务端没有全部处理完。于是数据就会积压起来,产生粘包。
解决: 解析包时, 递归解析处理
定义的读的 buffer 不够大,而数据包太大或者由于粘包产生,服务端不能一次全部读完,产生半包。
增大 buffer, 不同消息并发出来承受范围不同, 选取合适的 buff 长度即可
udp
- aaa
分布式锁
分布式锁可以解决在分布式环境下的多资源竞争问题,常见的分布式锁实现有以下3种:
- 基于数据库的唯一索引方式或乐观锁方式。
- 基于Redis单线程特性的原子操作。参考: Redis分布式锁的正确实现姿势 - https://benjaminwhx.com/2018/08/26/Redis分布式锁的正确实现姿势/
- 基于Zookeeper的临时有序节点。
缓存 数据库 更新
为什么不更新缓存后再更新数据库?
事务, 数据库更新失败
密码加盐
- golang 用 crypto/bcrypt 存储密码的例子 - https://golangnote.com/topic/44.html
进程守护
服务宕机后自动重启. 写个 shell 脚本, 然后在 定时任务 中加入 秒级 定时任务 调用这个脚本.
同时检测到进程需要重启服务时, 发一个 邮件/短信 通知相关人员. 可以别的某个服务的 http 服务中 (没有则起个 http goroutine), 添加一个发邮件的路由, 然后 shell 脚本中直接 curl 请求这个路由即可. 当然要加一些参数校验一下以便验证请求是自己发起的, 而不是被别人刷的.
消息中间件
kafka
- kafka解决了什么问题? - https://www.zhihu.com/question/53331259
单元测试
接口快速自测, 而不是等服务起来后再通过相关客户端去发起请求执行接口.
版本控制
主要是为了防止某次更新后出问题.
每次打包的 app 可执行程序, 配置表二进制数据 等都要记录 md5 并 备份一份, 用于某个更新后有问题可以 迅速,准确 回滚到 上一次正确的配置.