unity-合批优化
关于 unity 项目相关优化经验的墨迹
前篇
- 官方文档: Draw call batching - https://docs.unity3d.com/Manual/DrawCallBatching.html
- Unity3D - 图形性能优化:批量draw call - https://blog.csdn.net/ynnmnm/article/details/44650801
- Unity 绘图性能优化 - Draw Call Batching - https://www.cnblogs.com/fly-100/p/5422734.html
- Unity常见合批失败 - https://blog.csdn.net/zphshiwo/article/details/117386386
- Unity常见合批失败 - https://zhuanlan.zhihu.com/p/109200416
目的在于减少 cpu 与 gpu 交互的次数, 也就是所谓的 批次.
cpu 往 gpu 提交一次数据为 一个批次. 所以可以在 cpu 层做好 合批 的工作, 将原来需要多次提交的数据合拼到一个批次中提交.
所有合批的方式都有个核心的前提就是: 材质球要相同. 其实就是提交给 gpu 的数据相同, 材质球 封装了 往 gpu 提交的数据, 包好 贴图 和 一些uniform 变量.
在 unity 中, 如果通过 render.material 获取 材质球 的话, 其实获取到的是一个 复制拷贝后的 材质球副本, 就会从原来的合批中分离, 导致批次增加. 通过 render.sharedMaterial 获取的才是共享的 材质球 就不会, 但一旦改变, 所有引用这个材质球的mesh的表现都会改变.
合批的优先级是: static batching > instancing > dynamic batching.
1. Static Batching 静态合批
在另一方面, 静态合批 允许引擎为任何尺寸的几何降低draw call(如果它不移动,并且共用相同材质)。 静态合批 比动态批处理效果好得多,因为它需要消耗更少的CPU,所以你应该选择 静态合批 。
使用 静态合批 需要额外的内存来存储合并的几何。如果几个物体在批处理前共用相同的几何,那么在编辑器中或运行时,对每个物体都会创建一份几何的拷贝。
批处理不一定是好的,有时候对有些物体,你需要牺牲渲染性能来避免批处理,以减少内存消耗。比如,把一片浓密森林中的每一棵树标注为静态的,会消耗很大的内存。
静态合批 降低批次,而不是draw call数,draw call还是那么多,但是使用 静态合批 可以获得更快的效果。
使用流程
打开 静态合批 开关. file -> build settings -> player settings -> other settings , 勾选上 static batching
为了利用 静态合批 ,你应该显式指定某些物体是静态的,并且它不移动、旋转或缩放。你可以在检视器(Inspector)中使用Static checkbox来标明物体是静态的。
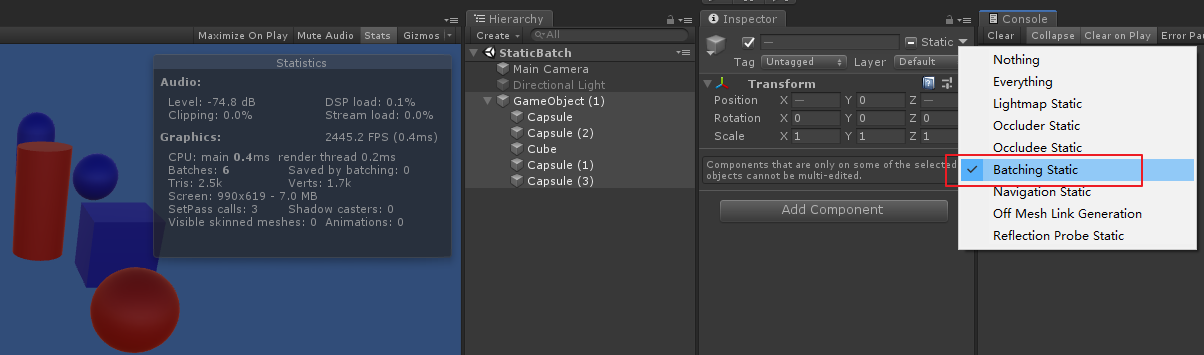
frame debug
静态合批 调试需要在运行时调试
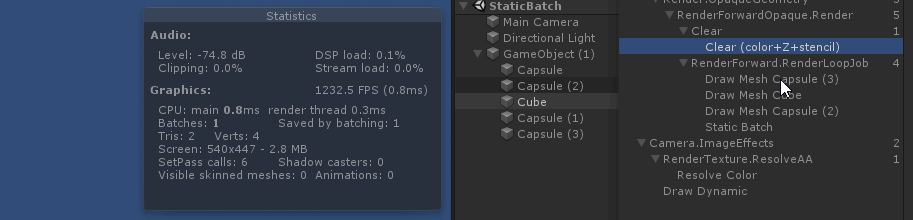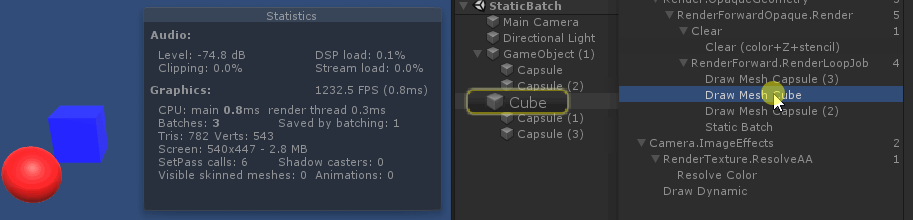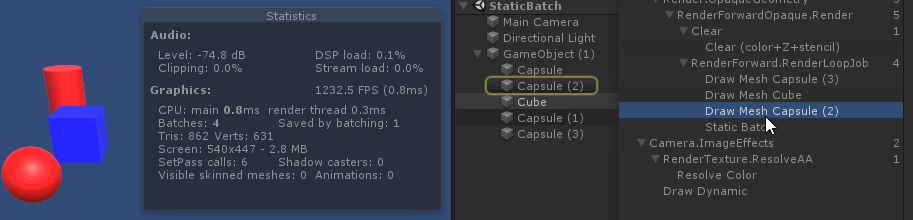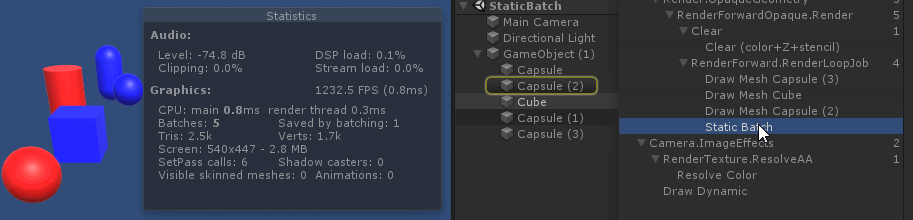
从绘制顺序上来看, 因为 unity 渲染 不透明物体时, 渲染顺序是由远 ( 参考总结: graphic-前向渲染管线浅析.md 中的 深度测试提前:Early-Z技术)
最远的两个会 静态合批
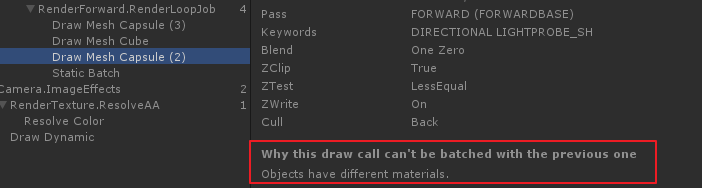
绘制中间的 cube 时, 打断了所有 sphere 和 圆柱体 的 静态合批. 原因是因为 cube 使用了 和 sphere,圆柱体 不同的材质
3. GPU Instancing
参考总结: unity-shader-GPU-Instancing.md
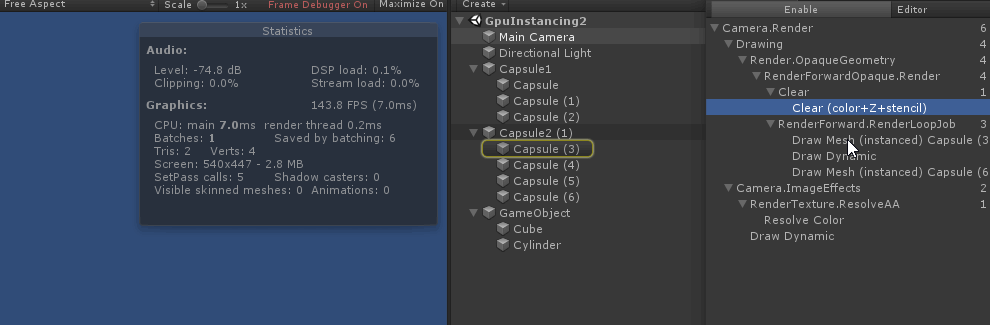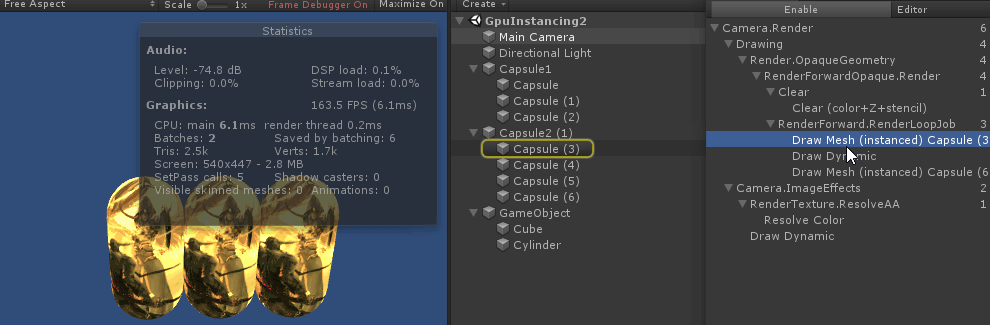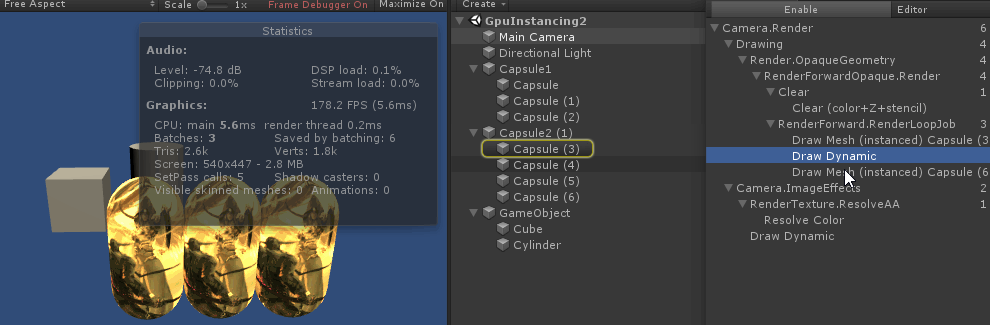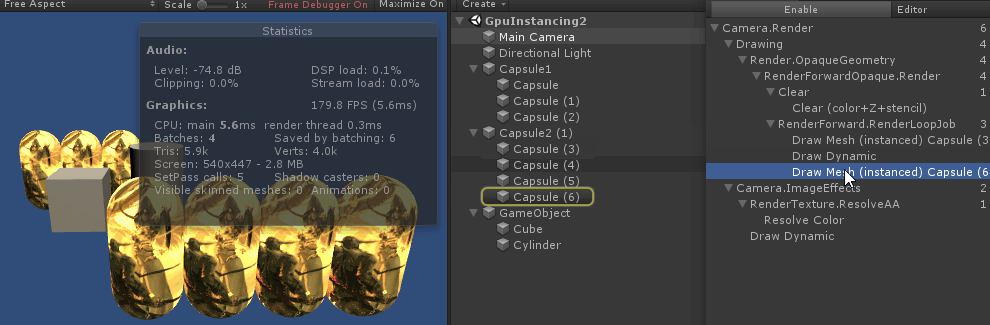
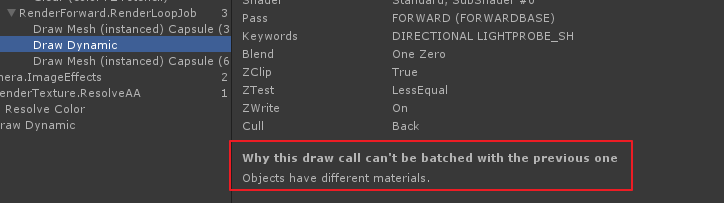
使用 Instancing, 貌似需要
"RenderType"="Opaque", 也就是 2000~2450 之间; 如果是在Transparent则不生效, 会断批```json
SubShader {Tags { "Queue"="Transparent" "RenderType"="Opaque" // 正常合批 // "RenderType"="Transparent" // 不能合批 }}
2. Dynamic Batching 动态合批
Unity可以自动批量处理移动的物体到相同draw call,如果他们共享相同的材质并且遵守其它标准。动态批处理是自动完成的,你不需要做任何事。
批处理动态物体在每个顶点有一定开销,所以批处理只对总共包含小于900个顶点的网格进行。
如果你的着色器使用顶点位置、法线和UV值,那么最多可以批处理300个顶点;如果你的着色器使用了 顶点位置、法线、UV0、UV1和切线,那么只能处理180个顶点。
- 一般的,物体应该使用相同的缩放。
- 例外是非统一缩放的物体:如果几个物体用不同的非统一缩放,那么它们可以批处理。【译注:这里的意思是,如果一个缩放(1,1,1)的物体和一个缩放(2,2,2)的物体不可以批处理;但是,缩放(1,2,1)的物体和缩放(1,3,1)的物体可以批处理】
使用不同材质的实例,即使他们本质上是相同的,但是物体不批处理到一起。含有lightmaps的物体有附加的渲染参数:lightmap 索引和偏移/缩放,所以,一般来说,为了批处理动态lightmap 的物体,应该严格的指向相同的lightmap部位。
多通道着色器会破坏批处理,几乎所有 unity 着色器在前向渲染时都支持几个灯光,并且为它们添加高效的附加通道。“附加的逐像素灯光”的draw call不会被批处理。
接受实时阴影的物体也不会被批处理。
一个 object 使用了 多个 pass, 也会打断合批
Other batching tips 其它批处理提示
目前,只有Mesh.Renderers和粒子系统使用批处理,蒙皮网格、衣服、尾迹渲染和其它类型的渲染组件并没有批处理。
半透明 shader 为了透明效果的需要,常常要求物体以由后向前的顺序渲染。Unity首先要求物体以这种顺序,然后试着批处理它们,但是因为顺序被严格限制了,所以,不透明物体比透明物体会获得更好的批处理效果。
Unity 的有些渲染还没实现批处理,比如渲染阴影投射、相机的深度纹理或者 GUI 将不会做批处理。
动态合批超过 32k 个顶点会新起一个批次
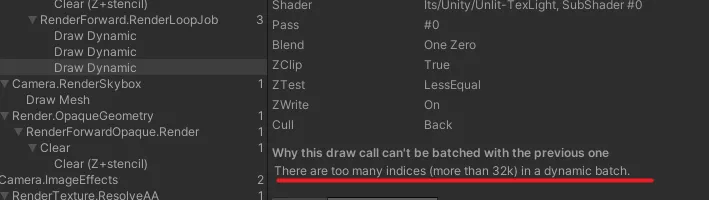
- 使用 gpu instance 就没有顶点限制
使用流程
- 打开 动态合批 开关. file -> build settings -> player settings -> other settings , 勾选上 static batching.
- 剩下的就是上面的注意事项, 避免打断合批
示例详解01
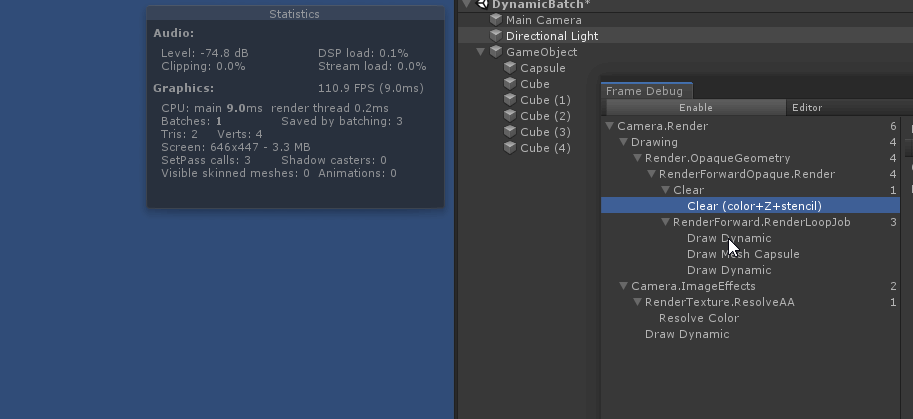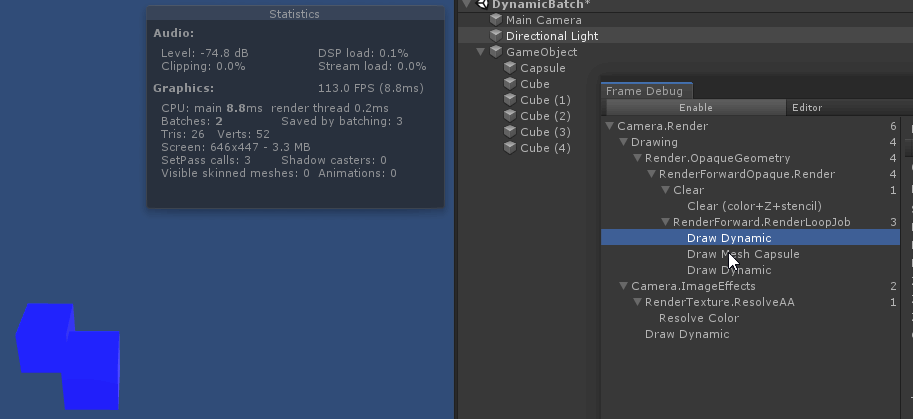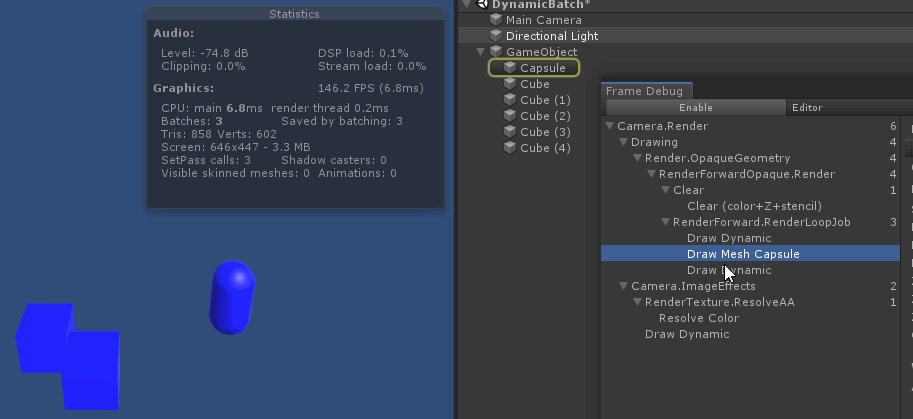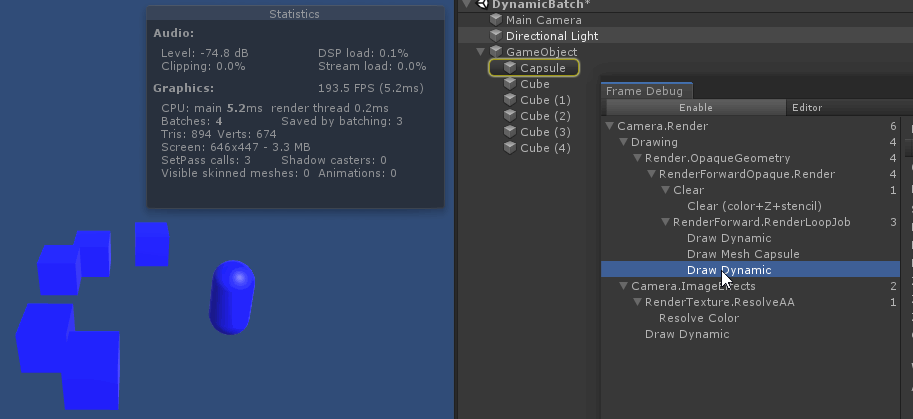
从绘制顺序上来看, 因为 unity 渲染 不透明物体时, 渲染顺序是由远 ( 参考总结: graphic-前向渲染管线浅析.md 中的 深度测试提前:Early-Z技术)
绘制中间的 capsule 时, 打断了所有 cube 的 动态合批. 原因是因为 capsule 的顶点数超过了300限制

如果把视角换到 从左往右 看, 那么 capsule 就是最后一个不透明物体, 就不会打断所有 cube 的 动态合批
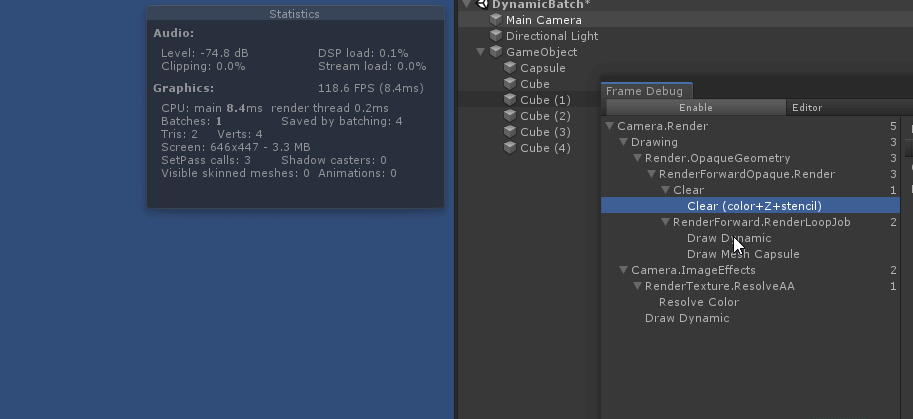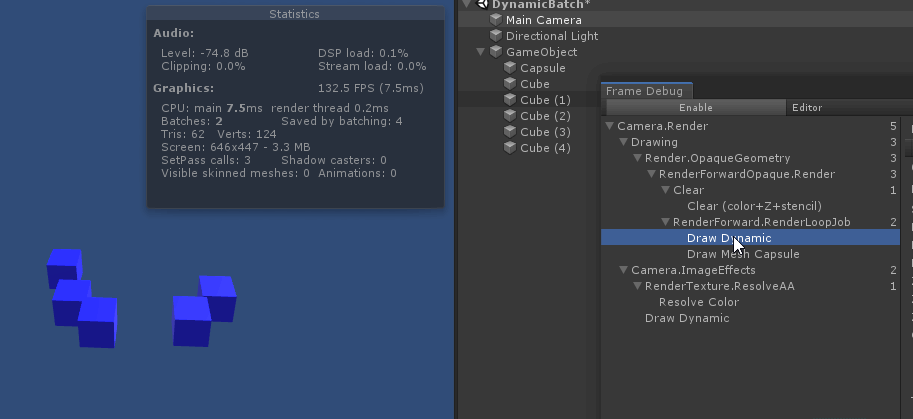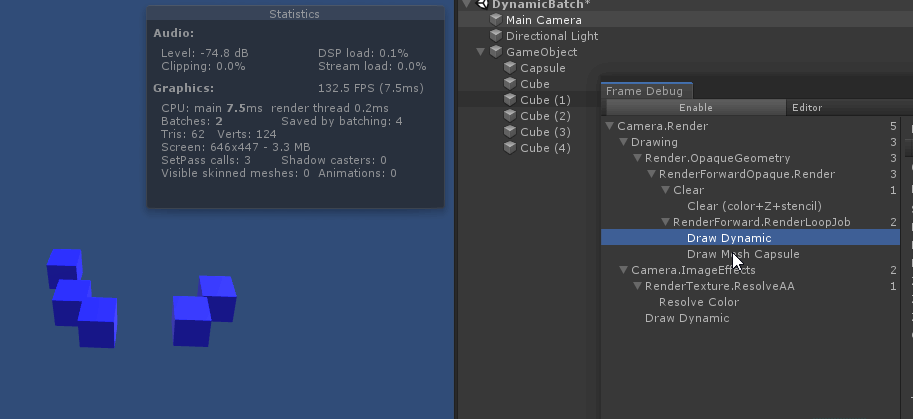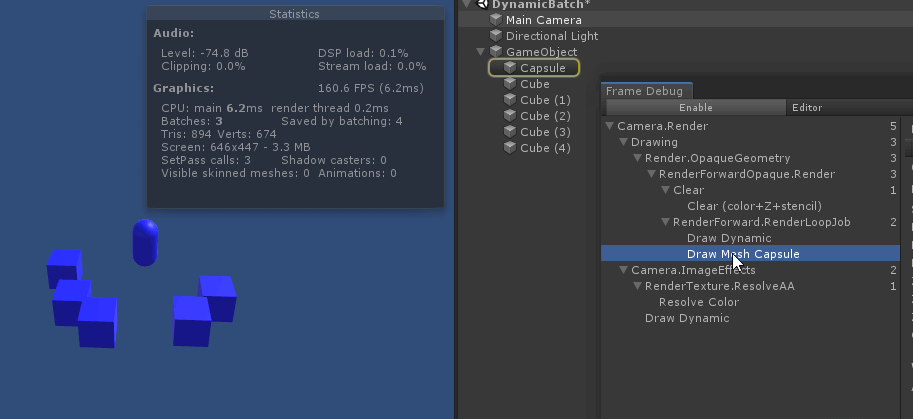
总结
因为 unity 渲染 不透明物体时, 渲染顺序是由远 ( 参考总结: graphic-前向渲染管线浅析.md 中的 深度测试提前:Early-Z技术)
所以这个很容易打断 静态合批 , gpu instancing, 动态合批 这三种合批方式. 需要注意这个问题.
frame debug 调试器
通过 unity 内置的 帧调试器, 可以看出每一帧的绘制情况, 要运行时去调试. 因为运行时才会 static batch.
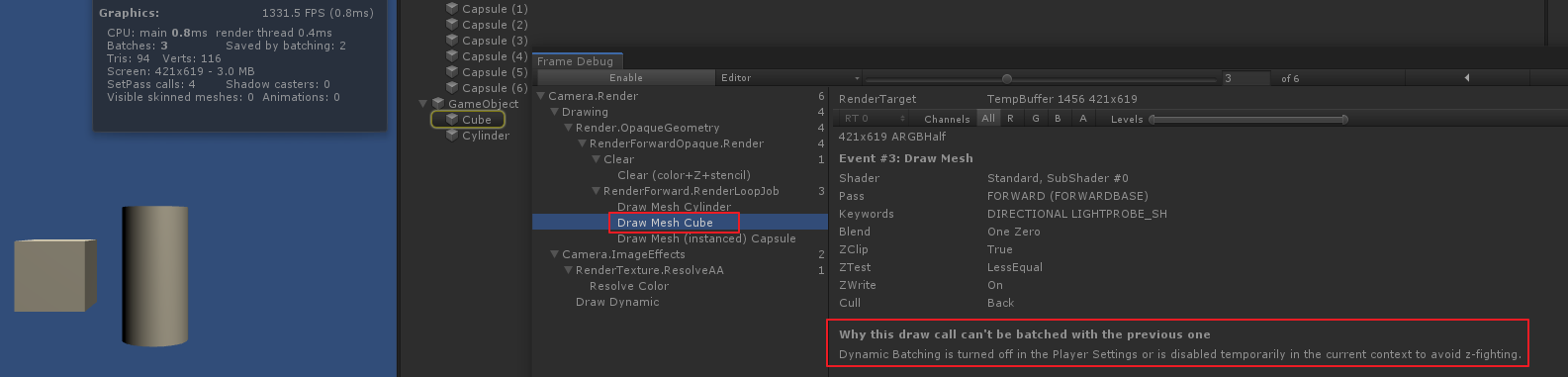
比如 cube 和 cylinder 应该是需要动态合批的, 但是实际上没有合批, 调试提示也很明显了, dynamic batch 开关没有打开.
3d 场景透明贴图渲染合批优化
渲染队列中, Transparent (透明, 默认: 3000) 渲染队列不能 gpu instancing,遮挡关系因为 go 的顺序间隔打断 instance
Geometry (不透明, 默认: 2000), 就不会因为 顺序打断,不透明物体的遮挡关系取决于深度
想要渲染 透明物体,又要使用 instance,就需要把 透明物体 的队列设置到 2000-2450 之间, 如:
"Queue"="Geometry+20", 让 unity 识别到要在 不透明渲染队列在中渲染, 同时不要写入深度,因为如果 物体x 的渲染队列更高, 同时深度又小于这个 透明物体 的话, 物体x 就不会渲染出来