algorithm-数据结构与算法记录
重温一下算法, 以此为记
前篇
- LeetCode - https://leetcode.com/problemset/algorithms/
- 网易公开课算法导论最短路径三部曲 - http://open.163.com/movie/2010/12/8/H/M6UTT5U0I_M6V2UDN8H.html
- LeetCodeAnimation - https://github.com/MisterBooo/LeetCodeAnimation
- LeetCode Solutions - https://github.com/azl397985856/leetcode
- 五大常用算法思想 - https://blog.csdn.net/zzd1506619299/article/details/52243128
- 9种经典排序算法可视化动画 - https://www.bilibili.com/video/av25136272/
- 算法可视化 - https://visualgo.net/zh
- labuladong 的算法小抄 - https://labuladong.gitbook.io/algo/
- 剑指 Offer 题解
图
广度优先搜索
深度优先搜索
A* 寻路
- 理解A*寻路算法具体过程 - https://www.cnblogs.com/technology/archive/2011/05/26/2058842.html
- A星寻路算法原理 - https://www.cnblogs.com/leoin2012/p/3899822.html
- A star Pathfinding [A星寻路算法] (视频) - https://www.bilibili.com/video/av32847834/
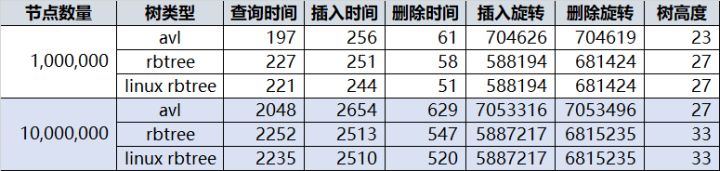
二叉排序树、红黑树、AVL树最简单的理解
- 二叉排序树、红黑树、AVL树最简单的理解 - https://blog.csdn.net/linshijun33/article/details/53455149
- 红黑树比 AVL 树具体更高效在哪里? - https://www.zhihu.com/question/19856999
二叉排序树
(BST) 是一棵具有下列性质的二叉树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结构的值
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结构的值
- 它的左子树和右子树都是二叉排序树
定义中最为关键的特点是,左子树结点一定比父结点小,右子树结点一定比父结点大
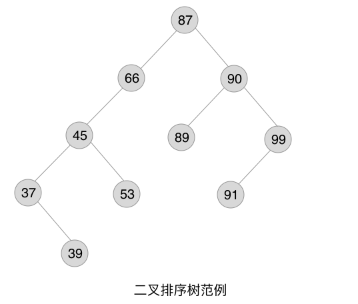
遍历打印可以使用 中序遍历 ,打印出来的结果是从小到大的有序数组。
平衡二叉树
平衡二叉树的定义(AVL)定义
平衡二叉树或者是一棵空树,或者满足以下的性质:它的左子树和右子树的高度之差的绝对值不超过1,并且左子树和右子树也是一个平衡二叉树。
平衡因子
左子树高度减去右子树的高度的值或者右子树高度减去左子树高度的值。显然 -1 <=bf <= 1
AVL树的引入
平衡二叉树在二叉排序树上引入的,在二叉树中,如果插入的节点接近有序,那么二叉树就会退化为链表大大降低了查找效率,为了使二叉树无论什么情况下最大限度的接近满二叉树,从而保证它的查找效率,因此引入平衡二叉树。
AVL树的实现
如何保证二叉树在任何情况下都能最大限度接近满二叉树,从而保证它的查找效率呢?那就是旋转,当平衡因子的绝对值大于1的时候,我们就需要对其进行旋转。
目的是加快 搜索, 但插入式代价大, 因为插入后要平衡的话就需要旋转
红黑树
- 红黑树详解—彻底搞懂红黑树 - https://blog.csdn.net/inspiredbh/article/details/60474958
- 红黑树(一)之 原理和算法详细介绍 - https://www.cnblogs.com/skywang12345/p/3245399.html
介绍
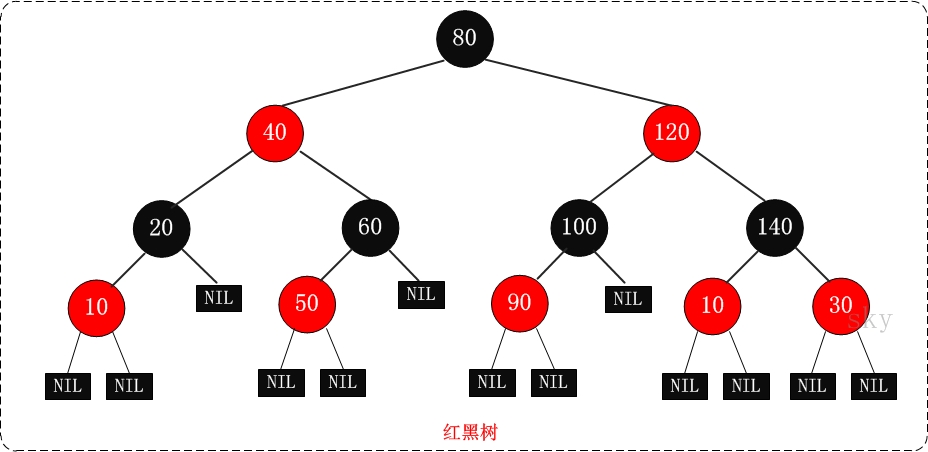
R-B Tree,全称是Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
注意:
(01) 特性(3)中的叶子节点,是只为空(NIL或null)的节点。
(02) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。
红黑树示意图如下:
应用场景
红黑树的应用比较广泛,主要是用它来存储有序的数据,它的时间复杂度是O(lgn),效率非常之高。
例如,Java集合中的TreeSet和TreeMap,C++ STL中的set、map,以及Linux虚拟内存的管理,都是通过红黑树去实现的。
csharp 集合类
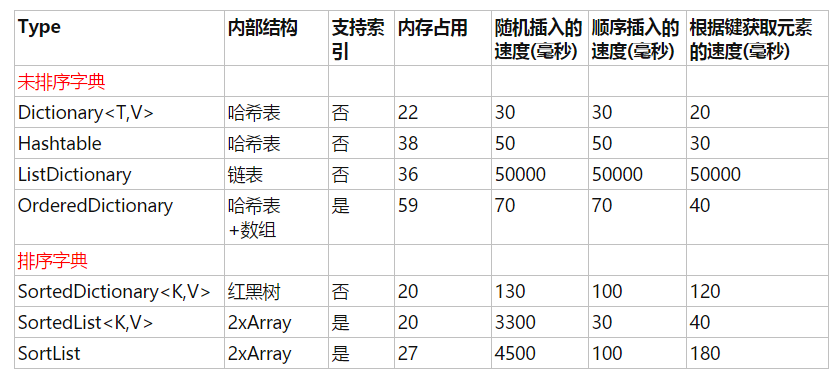
Dictionary 和 SortedDictionary
Dictionary :
计算key的hash值,并且找到buckets中目标桶的链首索引,2、从链上依次查找是否key已经保存,3、如果没有的话,判断是否存在freeList,4、如果存在freeList,从freeList上摘下结点保存数据,否则追加在count位置上。
buckets数组保存所有数据链的链首,Buckets[i]表示在桶i中数据链的链首元素。entries结构体数组用于保存实际的数据,通过next值作为链式结构的向后索引。删除的数据空间会被串入到freeList链表的首部,当再次插入数据时,会首先查找freeList链表,以提高查找entries中空闲数据项位置的效率。在枚举器中,枚举顺序为entries数组的下标递增顺序。
SortedDictionary :
SortedDictionary<K, V>是按照K有序排列的(K, V)数据结构,以红黑树作为内部数据结构对K进行排列保存– TreeSet
,红黑树是一棵二叉搜索树,每个结点具有黑色或者红色的属性。它比普通的二叉搜索树拥有更好的平衡性。2-3-4树是红黑树在“理论”上的数据结构。 2-3-4树插入算法:类似于二叉搜索树的插入(插入数据插入到树的叶子结点) ,如果插入位置是2-结点或者3-结点,那么直接插入到当前结点,如果插入位置是4-结点,需要将当前的4-结点进行拆分,然后再执行后继的插入操作。
SortedDictionary<TK, TV>通过TreeSet
实现,TreeSet 继承SortedSet ,SortedSet 是红黑树实现,不支持索引、具有O(logN)检索的二进制搜索树。类型安全、非线程安全。
SortedList<TK, TV>
具有O(logN)检索的二进制搜索树,双数组实现、支持索引。类型安全、非线程安全。
原理实现
SortedList<TK, TV>内部维护两个数组:一个键数组和一个值数组,与SortedList大同小异。
1 | private TKey[] keys; |
SortedList扩容:同样存在二次扩容问题,代码同ArrayList/List
动态规划
动态规划入门——详解完全背包与多重背包问题 - https://www.cnblogs.com/techflow/p/12572079.html
找零钱完全背包问题,LeetCode 322 - https://www.ixigua.com/6963552645755863589

如何理解动态规划? - https://www.zhihu.com/question/39948290/answer/883302989
通过金矿模型介绍动态规划 - https://www.cnblogs.com/SDJL/archive/2008/08/22/1274312.html